When Your AI Team Says "This is Beyond Your Understanding," Here's What's Actually Broken
When an engineering leader says, "What we are building is beyond your understanding," and a project is 9 months behind schedule, it's a cry for help.
By Greg Nudelman | Adapted from UXforAI.com for SOCForge.ai
"This is beyond your understanding."
The ML engineering lead said it with absolute confidence. The team at this security software startup was 9 months into building an investigation AI with nothing to ship.
His off-hand remark didn't surprise me. I've heard versions of it across dozens of AI projects since 2009. And it almost always means the same thing: the team is stuck on a problem that feels technically hard but is actually a requirements failure disguised as complexity.
85% of enterprise AI projects fail. In security, the number feels worse, because the consequences aren't just a bad user experience — they're missed threats, wasted analyst hours, and eroded trust that takes years to rebuild.
This team was about to become a statistic. Here's why — and what it looks like when you build it right.
The Netflix Profile Trap
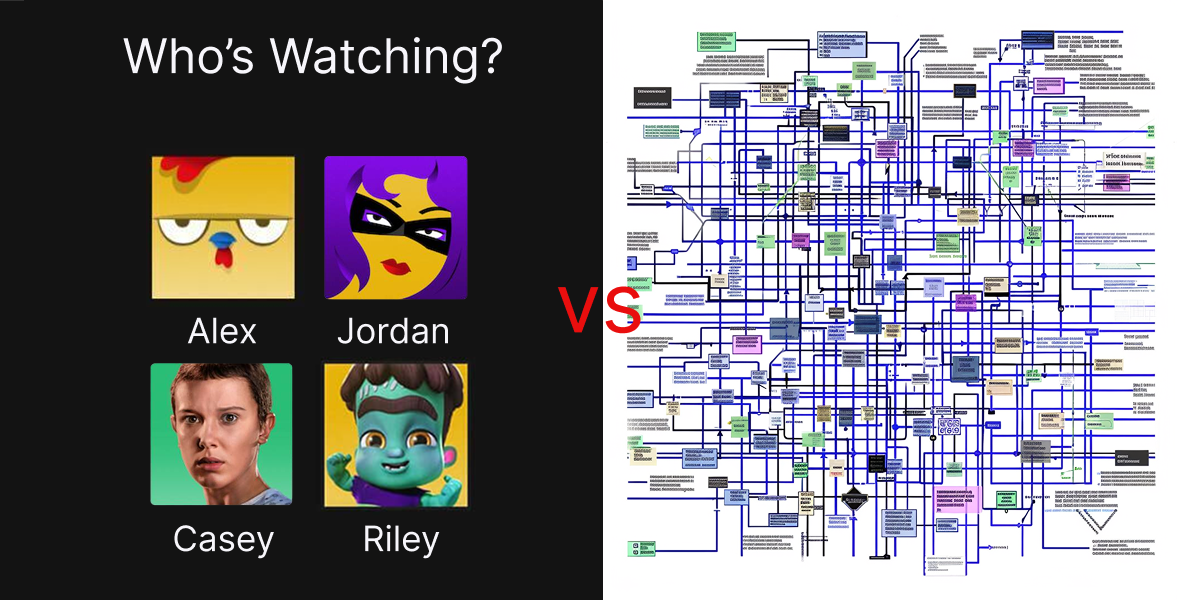
The AI was suggesting investigation steps — queries, correlations, next actions — when an analyst asked for help. Sounds useful. Except it was generating generic steps across every data type in the customer's environment. AWS CloudTrail. Azure AD. GCP. Apache. Microsoft 365. Okta. All at once.
Anyone who's built security investigation tooling knows why this is doomed. How you investigate a suspicious login in Microsoft 365 — the fields you query, the KQL syntax, the audit log structure — has little in common with investigating the same event in AWS CloudTrail, where you're writing Athena queries against JSON-structured events in a completely different schema.
I call this the Netflix Profile Trap. Netflix doesn't infer whether you want the Kids profile or the Adult profile from your search query. They just ask you to pick. Zero AI. Solves the right problem. This team was doing the opposite — forcing AI to guess the data source from the query and generate investigation steps that would somehow work everywhere.
That's not a hard ML problem. It's an impossible one. Every investigation step looked plausible in testing, but was overall unachievable. Analysts would try it once, get garbage, and never trust the feature again.
That's $2M and 9 months spent building acomplex AI to solve the wrong problem.
The Fix Was Obvious (Once You've Built It Before)
Talking with eight customers made it clear: analysts didn't want AI to guess which data type they were investigating and give them generic advice. They wanted AI to deeply understand their tech stack and generate deep and meaningful investigation steps highly specific to an aspect of their environment.
The insight hiding in plain sight: most Microsoft 365 customers start a basic investigation the same way. Most CloudTrail customers start the same way. The commonality isn't across all data types — it's within each one.
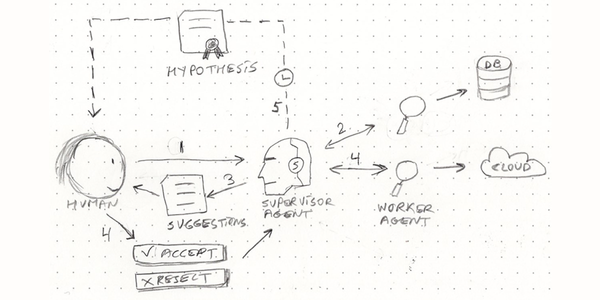
I recognized this pattern instantly because I'd already solved for it. When I built an autonomous SOC investigation platform at Sumo Logic, the critical architectural decision — the one that made everything else work — was that every investigation step starts by identifying the data source. The agents don't guess. They know what they're looking at before they generate a single investigative query.
That sounds obvious in hindsight. It wasn't obvious to the team that spent 9 months trying to build a universal investigation AI.
Thin Slice = Fewer Hallucinations
That's the gap many security AI teams don't see: the distance between "technically plausible" and "operationally useful" is where AI products go to die. AI without proper context hallucinates because it lacks the critical information about the tech stack. A generated investigation step that looks right but references the wrong field name, the wrong query syntax, or the wrong log structure is worse than no suggestion at all — it actively wastes analyst time and erodes trust.
The Lesson for Security AI Leaders
The team in this story got unstuck fast once the problem was reframed. Select a data source. Generate investigation steps custom to that data type. Ship an MVP for one source in weeks. Land and expand. Continuously improve the quality of investigation steps based on real analyst feedback.
But reframing only works if you've built the thing on the other side — if you've felt the pressure of analysts testing your investigation queries against real incidents at 2 AM, and learned through production failures that "works in POC" and "works in SOC" are different planets.
The pattern I keep seeing across security AI product orgs comes down to three questions.
- Are you shipping one data type at a time and nailing it, or trying to boil the ocean? The teams that beat the 85% failure rate don't start with the model. They start with the thin slice of real data.
- Does the AI know what data type it's looking at before it generates output? If not, chances are that the queries will be wrong, the correlations will be noise, and your analysts will work around the fancy AI feature within a week.
- When's the last time your AI engineers sat down with your analysts and reviewed the AI output for correctness? If that conversation isn't happening at least weekly, you have an ever-widening gap between SOC workflow reality and your LLM output. That gap is where security AI products live or die.
It's the problem I've spent 16 years solving — and it's the reason the things I build actually ship.
Greg Nudelman spent 16+ years shipping 34 AI products with $500M+ impact. Greg built an autonomous agentic SOC investigation platform in 2025, Forrester-rated at 166% ROI. He ships AI security and observability tools SOC teams actually use.